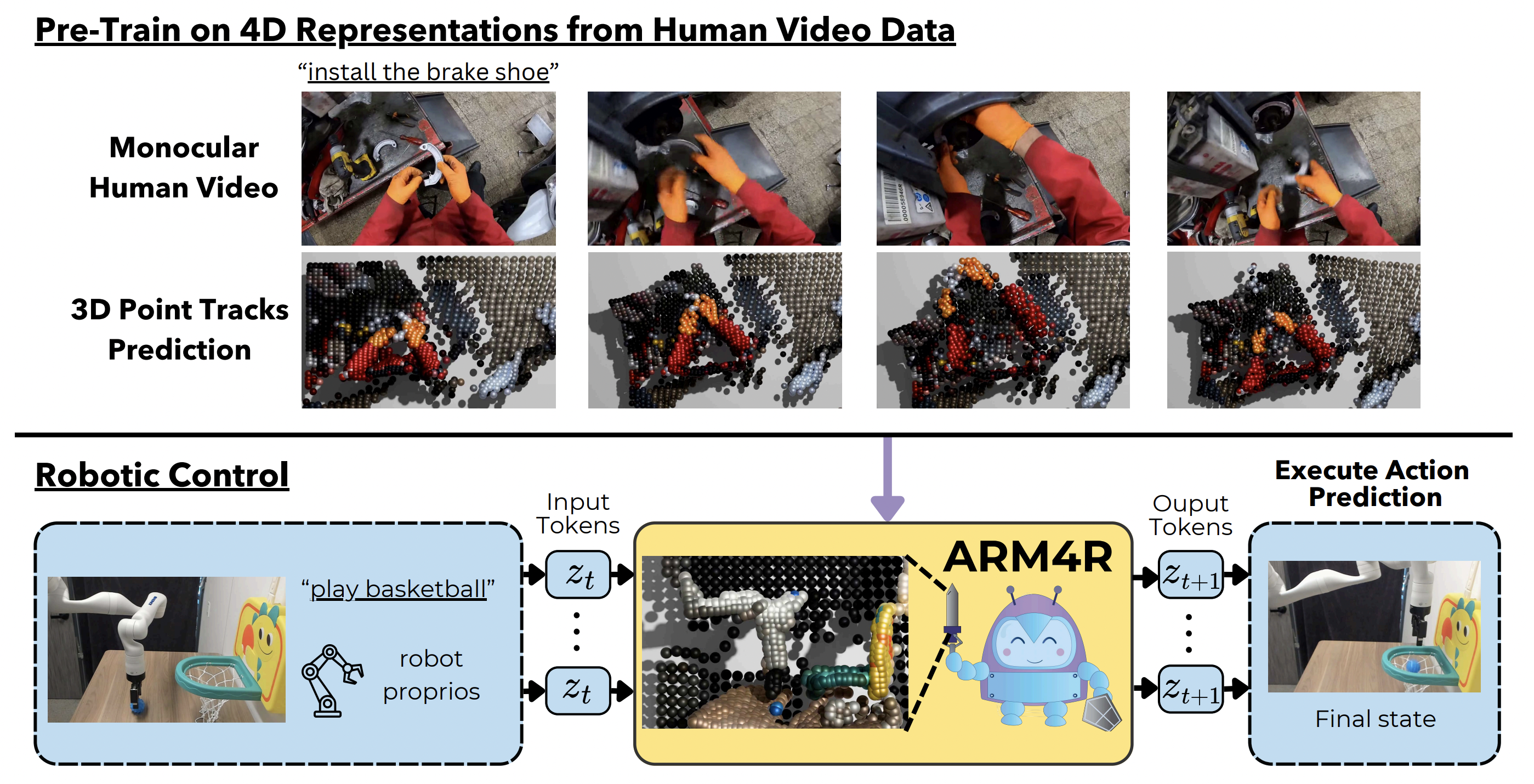
Abstract
Foundation models pre-trained on massive unlabeled datasets have revolutionized natural language and computer vision, exhibiting remarkable generalization capabilities, thus highlighting the importance of pre-training. Yet, efforts in robotics have struggled to achieve similar success, limited by either the need for costly robotic annotations or the lack of representations that effectively model the physical world. In this paper, we introduce ARM4R, an Auto-regressive Robotic Model that leverages low-level 4D Representations learned from human video data to yield a better pretrained robotic model. Specifically, we focus on utilizing 3D point tracking representations from videos derived by lifting 2D representations into 3D space via monocular depth estimation across time. These 4D representations maintain a shared geometric structure between the points and robot state representations up to a linear transformation, enabling efficient transfer learning from human video data to low-level robotic control. Our experiments show that ARM4R can transfer efficiently from human video data to robotics and consistently improves performance on tasks across various robot environments and configurations.4D Representations
Our 4D representations result from solving the 3D point tracking problem, which involves finding the 3D coordinates of discrete points across time, given a monocular video. As shown by our experiments, pre-training on these 4D representations benefits the downstream task of robotic control. We hypothesize this is because of the shared geometric structure — up to a linear transformation — between the 3D points and robot state representations.
These 4D representations are also generalizable enough to be usable with non-robotic data. As described in the next section, our main pre-training stage consists of egocentric human-object interaction videos.
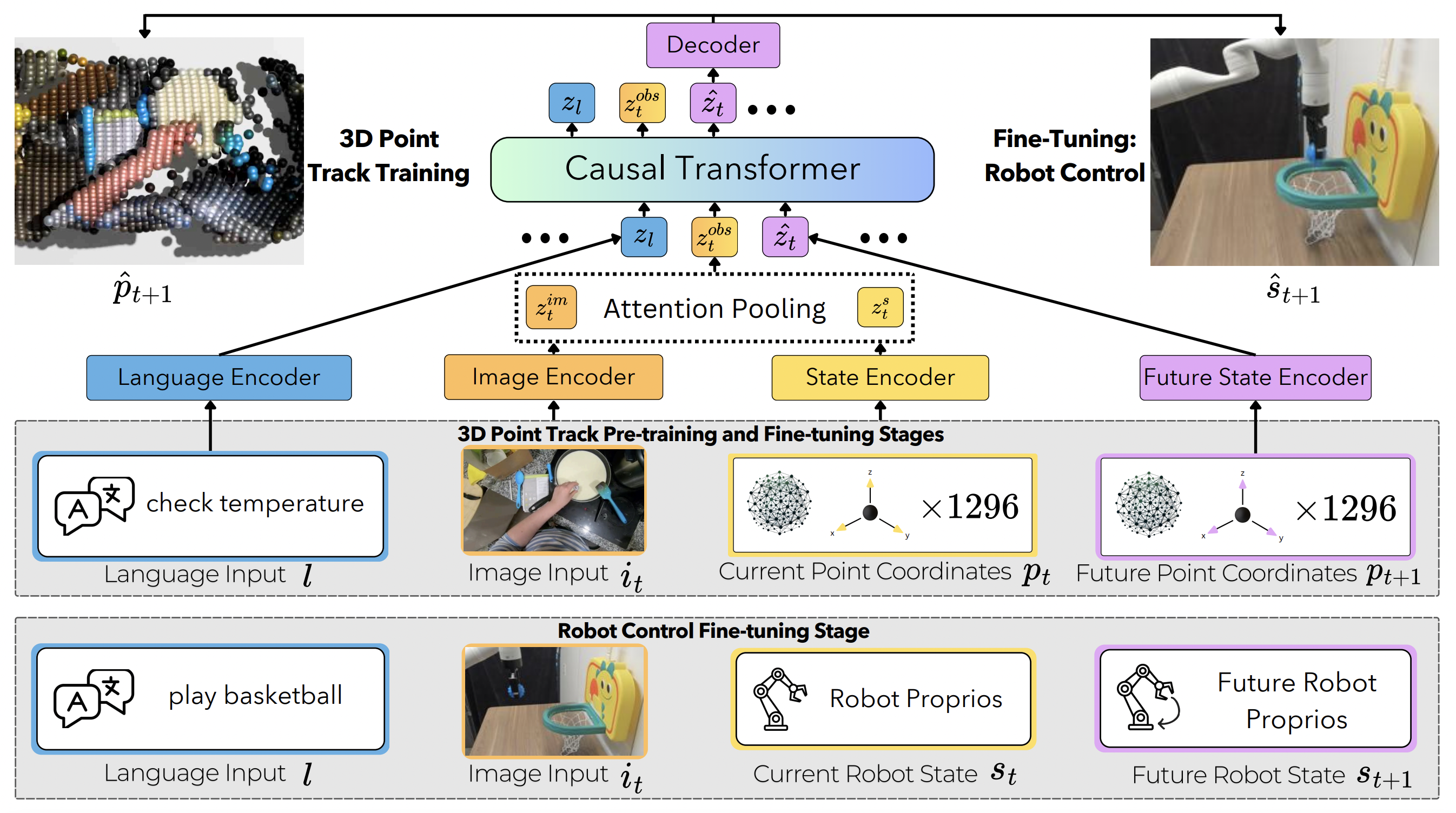
Methodology
ARM4R is trained in three stages:
Top Grey Box (Stages 1 and 2): The first two stages focus on learning a scene-wide 4D representation by predicting 3D points across time, where Stage 1 pre-trains on a large egocentric human dataset (EpicKitchens100), and Stage 2 fine-tunes on a smaller dataset (1-2K demonstrations) of robotic scenes. This step helps transition from the camera dynamics and embodiment gaps between the human video pre-training and the control fine-tuning in the next stage.
Bottom Grey Box (Stage 3): Finally, the model is fine-tuned to predict robot proprioceptive states rather than 3D points to enable robotic control.
Results
We evaluate ARM4R on 13 total tasks grouped into five categories, against several recent related works. It outperformed all tested baselines, including SoTA VLA methods π0 and OpenVLA. The results are presented in the table below.Average Success Rate (%) by Task Category
| Method | Pick Cube | Destack | Stack | Pick & Place Toys | Push Buttons | Overall Avg. |
|---|---|---|---|---|---|---|
| ATM | 7.1 | 6.7 | 2.0 | 10.3 | 2.0 | 6.4 |
| LLARVA | 46.7 | 9.3 | 9.2 | 9.3 | 11.7 | 18.3 |
| π0-FAST | 40.4 | 15.6 | 23.9 | 14.0 | 10.3 | 21.2 |
| OpenVLA | 71.8 | 53.5 | 33.2 | 18.0 | 11.6 | 37.2 |
| Ours | 96.0 | 94.7 | 61.6 | 92.7 | 54.8 | 83.1 |
BibTeX
@article{niu2025pre,
title={Pre-training auto-regressive robotic models with 4d representations},
author={Niu, Dantong and Sharma, Yuvan and Xue, Haoru and Biamby, Giscard and Zhang, Junyi and Ji, Ziteng and Darrell, Trevor and Herzig, Roei},
journal={arXiv preprint arXiv:2502.13142},
year={2025}
}